I have been playing around with the AWS SDK for Go V2 recently. And I was reading their Developer Guide for Testing, and was a little shocked that I had to mock every AWS API that I intended to use.
For many applications this isn't horrible, but it does require adding a lot of abstraction which kinda only makes sense if you are building for multi-cloud already. For many small projects, that isn't worth the upfront cost.
Smithy
Smithy is an interface definition language. It isn't focused on the wire format. Instead it focuses on the shapes and traits of an API. It sounds very academic, but it makes sense in practice.
AWS uses Smithy to define the API concepts and then generate clients for different languages from there. There was a good Hacker News post on the topic a few years ago.
One of the nice things that Smithy brings to the AWS SDK is the ability to manipulate the request/response pipeline to do some interesting things. In this post I'm going to use it to add mocking to existing AWS SDK APIs.
Smithy-go Middleware
Smithy-go has a Middleware concept that it uses to perform all of the necessary transformations from Golang SDK objects into the wire format used by the AWS APIs. I found this diagram to be an easy way to digest the different stages of the middleware.
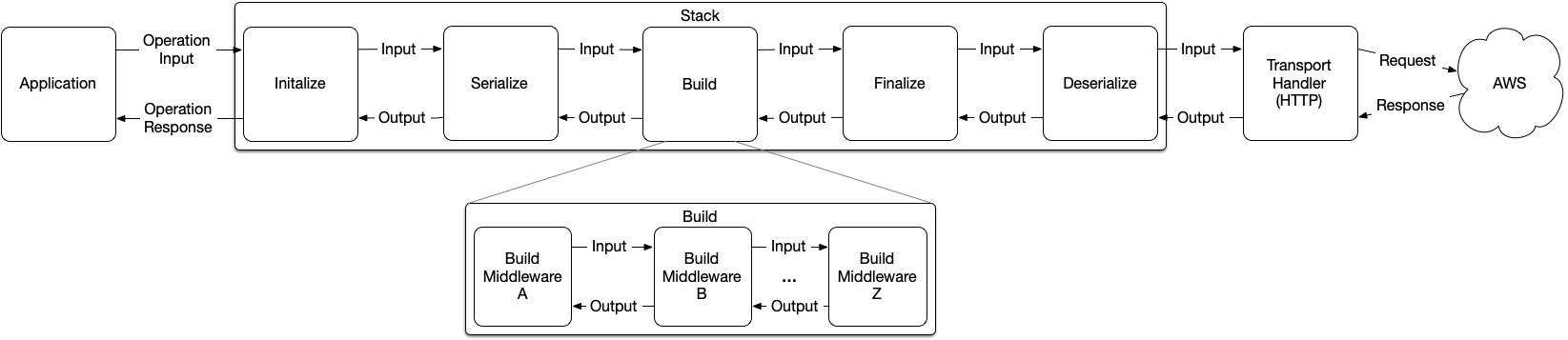
For the purposes of adding mocking and avoiding actual calls to AWS, I decided to hook into the Initialize stack step.
InitializeMiddleware is Initializing Middleware
Making a middleware that executes a custom function and short-circuits the call to AWS is relatively trivial:
// MockingStackValue is the collection of values to return instead of executing
// the called service.
type MockingStackValue struct {
Output interface{}
Metadata middleware.Metadata
Error error
}
// MockingMiddleware implements initiatlize and finalize middleware stages. It
// executes `Test` at at the end of the Initialize Stage to influence what is
// returned at the end of the finalize stage.
//
// See github.com/aws/smithy-go/middleware for more details on the stages.
type MockingMiddleware struct {
Name string
Test func(interface{}) (bool, MockingStackValue)
}
// ID returns the Name field.
//
// ID is required by the Middleware interfaces.
func (mocker *MockingMiddleware) ID() string { return mocker.Name }
// HandleInitialize runs the test function to configure how the middleware will
// handle the Finialize stage.
//
// HandleInitialize is required by the InitializeMiddleware interface.
func (mocker *MockingMiddleware) HandleInitialize(
ctx context.Context,
in middleware.InitializeInput,
next middleware.InitializeHandler,
) (middleware.InitializeOutput, middleware.Metadata, error) {
if passed, out := mocker.Test(in.Parameters); passed {
return middleware.InitializeOutput{
Result: out.Output,
}, out.Metadata, out.Error
}
return next.HandleInitialize(ctx, in)
}
MockingStackValue isn't required, but I wanted it to simplify the signature of the Test function. The MockingMiddleware type wraps the Test function in way that allows it to make a decision to short-circuit the AWS call. The Method ID() just required by the InitializeMiddleware interface. As is HandleInitialize().
The simplest way to leverage this middle ware is to add the mocking object to the Config object. This ensures that the mocking object has an opportunity to intercept all AWS calls:
ctx := context.TODO()
cfg, err := config.LoadDefaultConfig(
ctx,
func(opts *config.LoadOptions) error {
mocker := MockingMiddleware{
Name: "dynamodb-mocker",
Test: mockDDBResult,
}
opts.APIOptions = append(opts.APIOptions, func(stack *middleware.Stack) error {
return stack.Initialize.Add(mocker, middleware.After)
})
},
)
if err != nil {
log.Fatalf("Unable to configure AWS client %v", cfg)
}
There is a lot of AWS/Smithy boilerplate there, but the main idea is that the mocking object is passed in as a configuration option function. If you prefer to add the configuration steps outside of the configuration load, you can follow the guidance in the AWS documentation.
In my application, I implemented something that allows for attaching steps per API call. The App is a lambda, so there isn't a lot of depth to the application, which makes updating the calls to pass the option functions easier:
type AppContext struct {
AwsConfig config.Config
Ddb *dynamodb.Client
DdbOptFns []func(*dynamodb.Options)
}
func NewAppContext(ctx context.Context) AppContext {
cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
log.Fatalf("Unable to configure AWS client %v", cfg)
}
return AppContext{
AwsConfig: cfg,
Ddb: dynamodb.NewFromConfig(cfg),
}
}
func (app AppContext) BusinessLogic(
ctx context.Context,
request events.APIGatewayProxyRequest,
) (events.APIGatewayProxyResponse, error) {
...
result, err := app.Ddb.Query(ctx, &queryIn, app.DdbOptFns...)
if err != nil {
return events.APIGatewayProxyResponse{}, err
}
...
}
func TestHandler(t *testing.T) {
ctx := context.TODO()
app := NewAppContext(ctx)
app.DdbOptFns = []func(*dynamodb.Options){
func(opts *dynamodb.Options) {
mm := &MockingMiddleware{
Name: "customer-query",
Test: mockCustomerQuery,
}
opts.APIOptions = append(opts.APIOptions, func(stack *middleware.Stack) error {
return stack.Initialize.Add(mm, middleware.After)
})
},
}
...
response, err := app.TimelineHandler(ctx, request)
}
I don't particularly like that app.DdbOptFns... hanging off the end of the call like that. I'll probably spend some time seeing if I can make it disappear without having to wrap every single client.
I prefer this approach as it allows me finer control over which API calls get mocked and which are treated more like an integration test.
Other Thoughts
Another approach I might investigate is making the decision to mock at the Initialize stage of the stack, and then changing the result at a different stage of the stack. One example of doing this would be to fake the wire protocol response in Deserialize stage. The advantage of manipulating the mock in this was is to preserve most of the expectations on what the AWS SDK normally does, in terms of authentication, etc. The AWS SDK has details for how to pass the metadata towards AWS.
I'm starting to like the "shape" approach used by smithy for defining APIs. It could be interesting to see what the effort is to implement my APIs in Smithy and generate the clients. We have a lot of conversations at Datadog about Services, Resources and Operations, and the bullet points in the Smithy Quickstart have given me some new perspective on those topics.